OWN: The Judgment Side of Working with AI
Caleb Woods

Getting better output from AI starts with better input. But what happens after the AI responds is where most people get caught. OWN is the judgment side of working with AI. Observe what the AI did. Weigh what's at stake. Distill and put your Name on it.
SHARE POST
Getting better output from AI starts with better input. That's what CRAFT is for. But better input only solves half the problem.
The other half is what happens after the AI responds. Most people read the output, decide it looks reasonable, and use it. That works until it doesn't. Until a confident-sounding answer turns out to be wrong. Until a number that felt right has no source behind it. Until something you shared with a partner has a claim in it you can't explain.
AI fails differently than a colleague. A teammate doesn't confidently fabricate a statistic. A teammate doesn't give you a detailed answer to a question they never actually looked into. AI will do both, and the output will read just as polished either way.
OWN is the framework we use at RoleModel Software for the judgment side of working with AI. Three steps, each one a habit worth building.
CRAFT the input. OWN the output.

Observe What It Did
Before you evaluate the output, understand how it got there.
Modern AI tools can do real work: read files, search the web, run queries, pull up documentation. When the tool did that work, the answer is grounded in actual data. When it answered without checking, it generated from training data. That's not always wrong, but it tells you what kind of output you're holding.
The distinction matters. An answer backed by a web search has sources you can check. An answer generated without checking may be approximate, outdated, or fabricated entirely. Both will sound equally confident.
Here's what this looks like in practice. You ask the AI about a library's API. If it read the documentation or checked the source code, the answer reflects the current state. If it just answered, it may be describing a method signature that changed two versions ago, or one that never existed.
Same principle outside of code. You ask for a statistic about an industry trend. If it searched the web, the number has a source you can trace. If it just answered, you're trusting a response generated from training data that may be a year or more out of date.
The habit is simple: before you act on the output, notice whether the AI did any actual research to produce it. "I didn't see you do any research" is a valid and useful observation. You're reviewing the process, not just the result. The same way you'd evaluate a colleague's work differently if they said "I looked this up" versus "I think I remember."
Weigh the Stakes
Not every output needs the same level of scrutiny. A personal brainstorm and a production deliverable are different animals. Treating them the same wastes time in one direction and creates risk in the other.
Two axes help you calibrate.
The first is what's at stake. A personal working note or exploration needs a quick sanity check. Something shared with your team needs a structural review. A production deliverable or anything affecting partners needs source verification on every claim.
The second is what type of work the AI produced. Qualitative work like writing, structure, and framing is where the model is generally reliable. Spot-check the logic and tone. Quantitative work with numbers, data, and percentages is where the model is unreliable. Verify everything numeric. Factual work with verifiable claims, citations, or current data is where the model may fabricate or be stale. Confirm it actually searched rather than recalling from training.
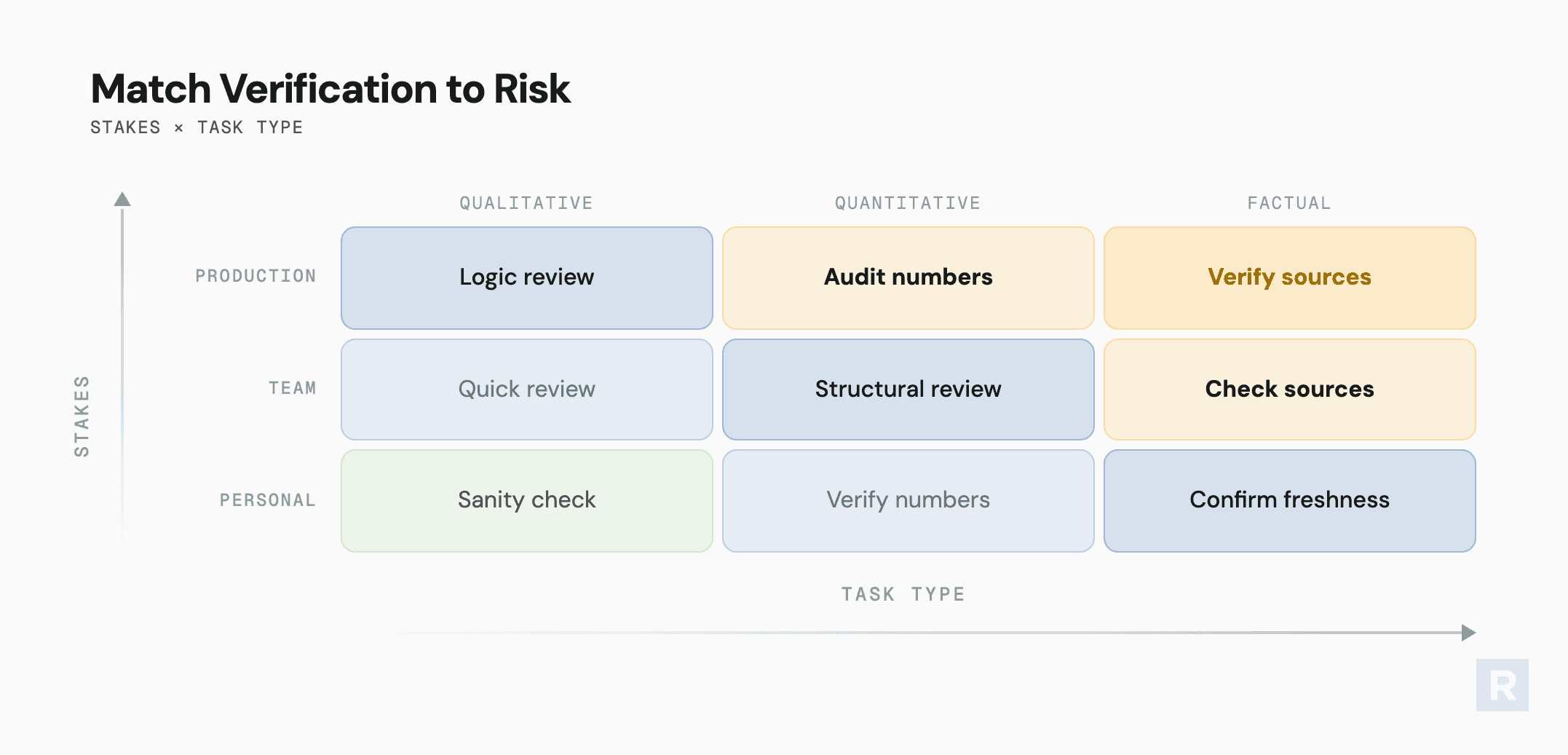
The intersection of those two axes gives you a verification protocol. A qualitative summary for your team needs a logic review. A quantitative claim in a production deliverable needs you to audit the numbers. Factual claims at any level of stakes need you to verify the sources.
That calibration breaks down in three predictable ways. Over-trusting: accepting output without checking, especially anything quantitative or current. Under-using: so skeptical of every response that you redo everything from scratch. That's just expensive double entry. Not iterating: treating the first output as the final output, then concluding the tool doesn't work.
Don't over-verify low-stakes work. That's waste. Don't under-verify high-stakes work. That's risk. Calibrate.
Name It Yours
The moment you share AI-generated output, it carries your name. This isn't about pride. It's about professional responsibility.
"The AI said" is not a defense. If a partner or colleague pushes back on something you shared, "I can explain the reasoning" is the only answer that holds up. "I can point you to the tool that produced it" is not.
Volume is free. Clarity is the work. It's easy to generate a 15-page document. It's harder and more valuable to distill that down to the one page that's actually digestible and actionable. The act of distilling is the act of owning. You can't condense something you don't understand. If you find yourself unable to cut the output down, you haven't engaged with it deeply enough.
Before sharing anything, run a simple test: would you be comfortable defending every claim in this document in a meeting? If not, it's not ready.
AI makes you faster. The standard for what carries your name doesn't change.
OWN in Practice
The framework is simple. The habit takes repetition.
Before you read the output: Observe. What did the AI actually do to produce this?
Before you verify: Weigh. What's at stake, and what type of work is this?
Before you share: Name. Can you defend this? Have you distilled it to what matters?
The teams getting the most from AI aren't the ones using better tools. They're the ones applying better judgment to what the tools produce.